

Die nichtlineare Optimierung gehört zu den sog. NP-harten Problemen, d.h. die Komplexität des Algorithmus, also die Anzahl der durchzuführenden Rechenoperationen wächst schneller als polynomial (Nicht Polynomial) mit der Komplexität des Problems. Im Falle der Optimierung von Polynomen wächst die Komplexität des Problems mit der Zahl der Variablen, mit dem Grad des Polynoms und mit der gewünschten Genauigkeit.
Die Komplexitätstheorie der Informatik zeigt, daß alle NP-harten Probleme zueinander gleichwertig sind [HU90, S.353,],[Kar86]. Diese Aussagen beziehen sich stets auf allgemeine Probleme, d.h. es gibt keinen Algorithmus, der alle nichtlinearen Polynome in polynomialer Zeit optimieren kann. Über kleinere Klassen von Polynomen macht die Komplexitätstheorie keine Aussage, insbesondere wenn es um die mathematisch schwer definierbare Klasse der physikalisch relevanten Polynome geht. Die Aussagen der Komplexitätstheorie lassen sich deshalb nur beschränkt zur Entwicklung besserer Algorithmen nutzen [Zen92].
Der oben beschriebene Algorithmus ist eine neue Methode, mit der man in praxi das Problem der nichtlinearen Optimierung angehen kann. Er ergänzt andere Methoden, indem er für eine andere Teilklasse von Problemen geeignet scheint als bisher bekannte Verfahren.
Das Problem bei der nichtlinearen Optimierung liegt darin, daß man nicht
jede ,,Ecke`` des Definitionsgebietes untersuchen kann, weil es einfach
in einem hochdimensionalen Raum zuviele davon gibt. Wollte man sich
rein numerisch einen Überblick über den Verlauf einer Funktion mit
100 Variablen verschaffen, indem man pro Variable an 4 Stützstellen
den Funktionswert bestimmt, so müßte man 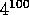 Funktionswerte
berechnen, was auf einer CRAY Y-MP etwa
Funktionswerte
berechnen, was auf einer CRAY Y-MP etwa 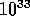 Jahre brauchen würde
[Ebe89].
Jahre brauchen würde
[Ebe89].
Die eine Strategie, um ohne die Beleuchtung jedes Winkels auszukommen, ist die Verwendung stochastischer Algorithmen (Simulated Annealing, Genetische Algorithmen), die allerdings aufgrund ihrer Natur nicht immer das Optimum finden.
Der oben beschriebene Algorithmus umgeht das Problem dadurch, daß analytisch berechnete Unter- und Obergrenzen es ermöglichen, ganze Teilintervalle von der weiteren Untersuchung auszuschließen. In jedem Teilschritt werden nur absolut sichere Aussagen erzielt.
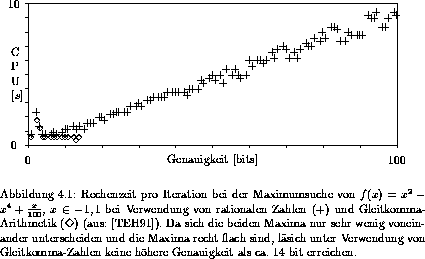
Die Rechenzeit wächst im allgemeinen bei weiterer Verfeinerung des Gitters kaum an, da die Zahl der zu untersuchenden Teilintervalle ungefähr konstant bleibt. Das Anwachsen ist auf die länger werdenden rationalen Zahlen zurückzuführen, die durch ihre ,,unendliche Genauigkeit`` numerische Probleme ausschließen.
Ein Testlauf für ein Problem mit 100 Variablen benötigte auf
einer SUN 3/50 drei Tage, verschwindend kurz im Vergleich
zu 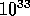 Jahren!
Jahren!
Während der ersten Iterationen können normalerweise nicht alle Intervalle bis auf eines eliminiert werden. Dadurch wächst die benötigte Rechenzeit pro Iteration zunächst an. Jedoch verbessert sich die Güte der Abschätzungen, wenn die Intervalle kleiner werden, so daß in den folgenden Iterationen die Zahl der Intervallkandidaten wieder drastisch sinkt. Die Rechenzeit bleibt dann nahezu konstant, wenn Gleitkomma-Arithmetik verwendet wird. Bei Verwendung von rationaler (exakter) Arithmetik steigt die Rechenzeit etwa linear mit der Zahl der zur Darstellung der Intervallgrenzen benötigten Ziffern (vgl. Abb. 4.1).